



If you’re reading this blog post, you’re likely familiar with the pull toward more metrics. As organizations grow, so too does the list of things people want to measure. Different metrics matter for different teams, and everyone has Metrics FOMO, worried that leaving one out could prevent us from reaching our Next Big Insight.
At Discord, this happened with our Default Metric List: a set of metrics that are automatically included in every experiment. Over time, that default list grew as teams added metrics they cared about, while few were removed. We took a step back and asked if we might be better off measuring less.
To data teams, suggesting we measure less feels like heresy. “Our job is to measure! Why would we, the organization’s shrewdest pattern finders, knowingly leave data on the table?” The encounter below might look familiar:

This urge is real, but having too many metrics brings a new set of issues. Beyond higher compute costs and a harder time navigating experiment readouts, having more metrics highlights an inherent tradeoff:
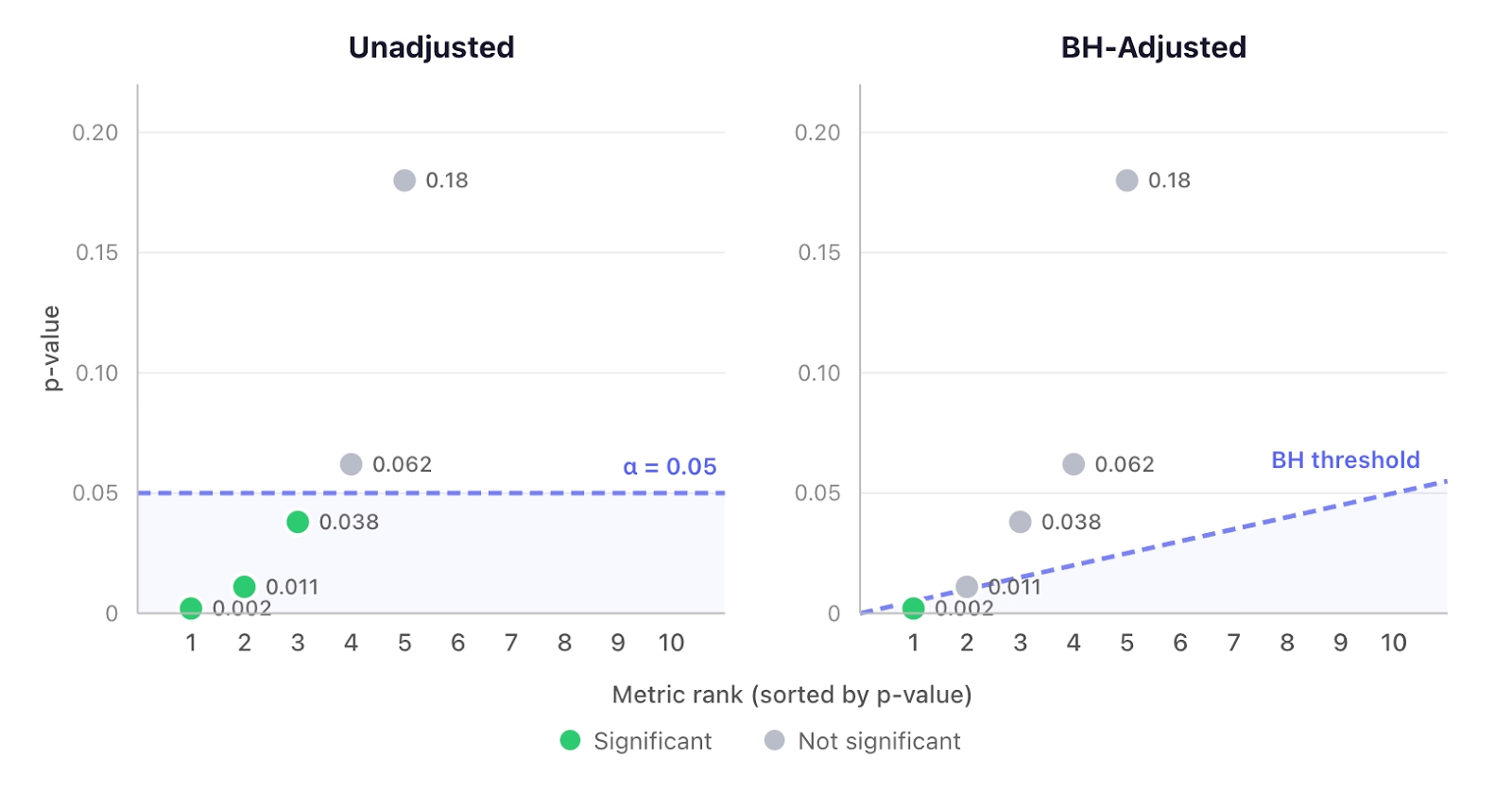
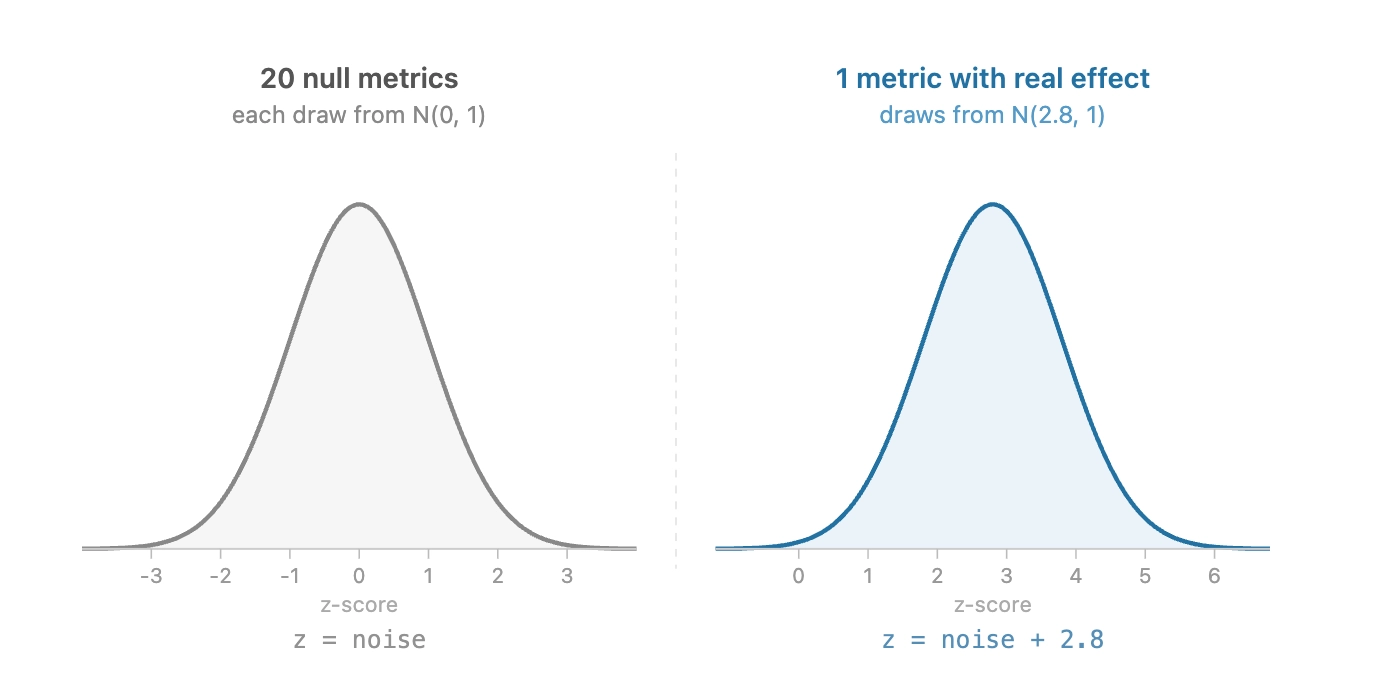
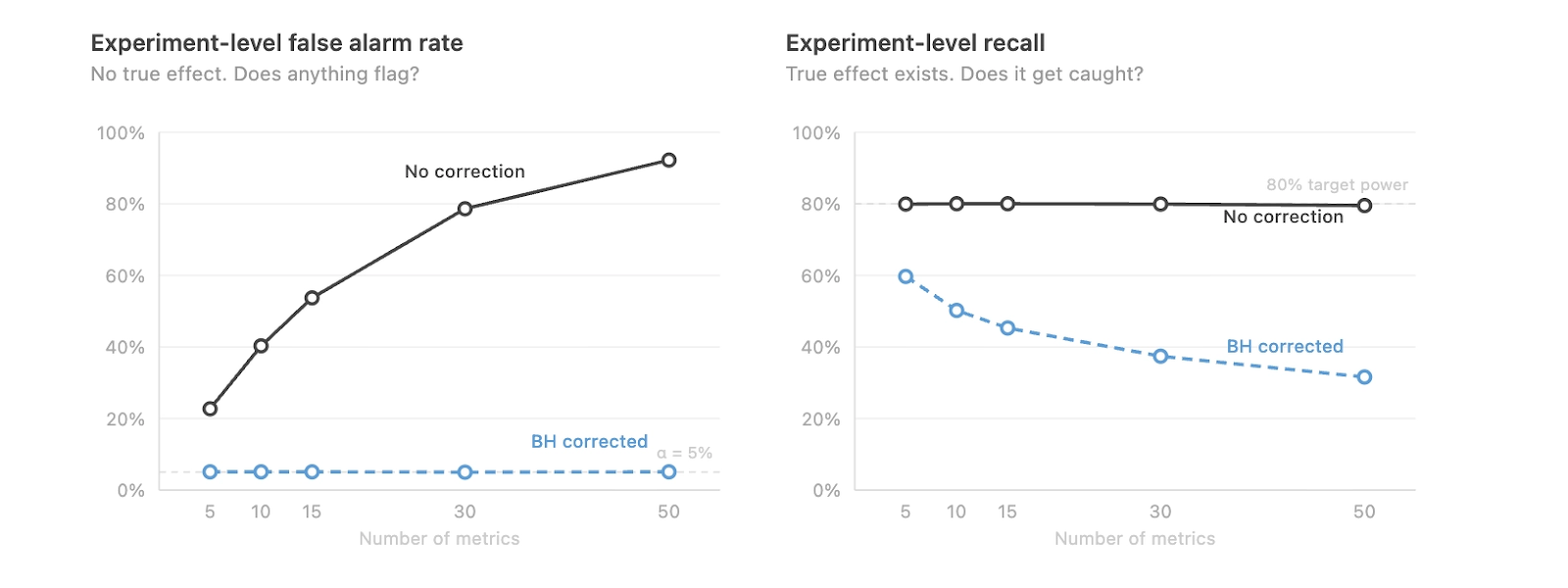
- Leaving p-values as-is has the potential for too many false positives. For example, if you have 100 metrics and set a 5% p-value threshold for statistical significance, 5 of your metrics are going to be statistically significant just by random chance.
- Adjusting p-values using a multiple hypothesis correction can result in fewer false positives, but worse recall in detecting real changes. In this situation, ”Recall” is defined as the proportion of true positives that we catch.
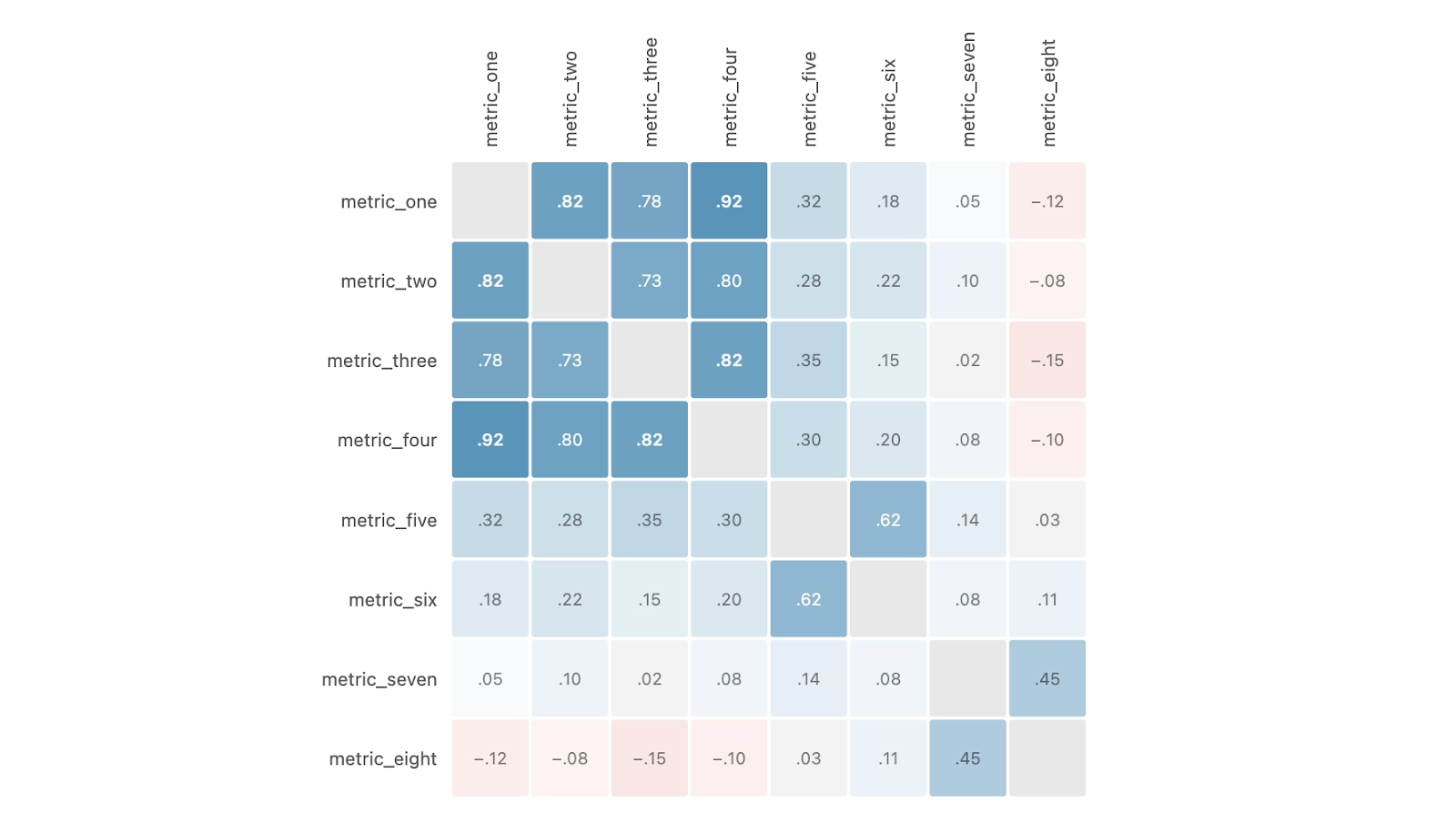
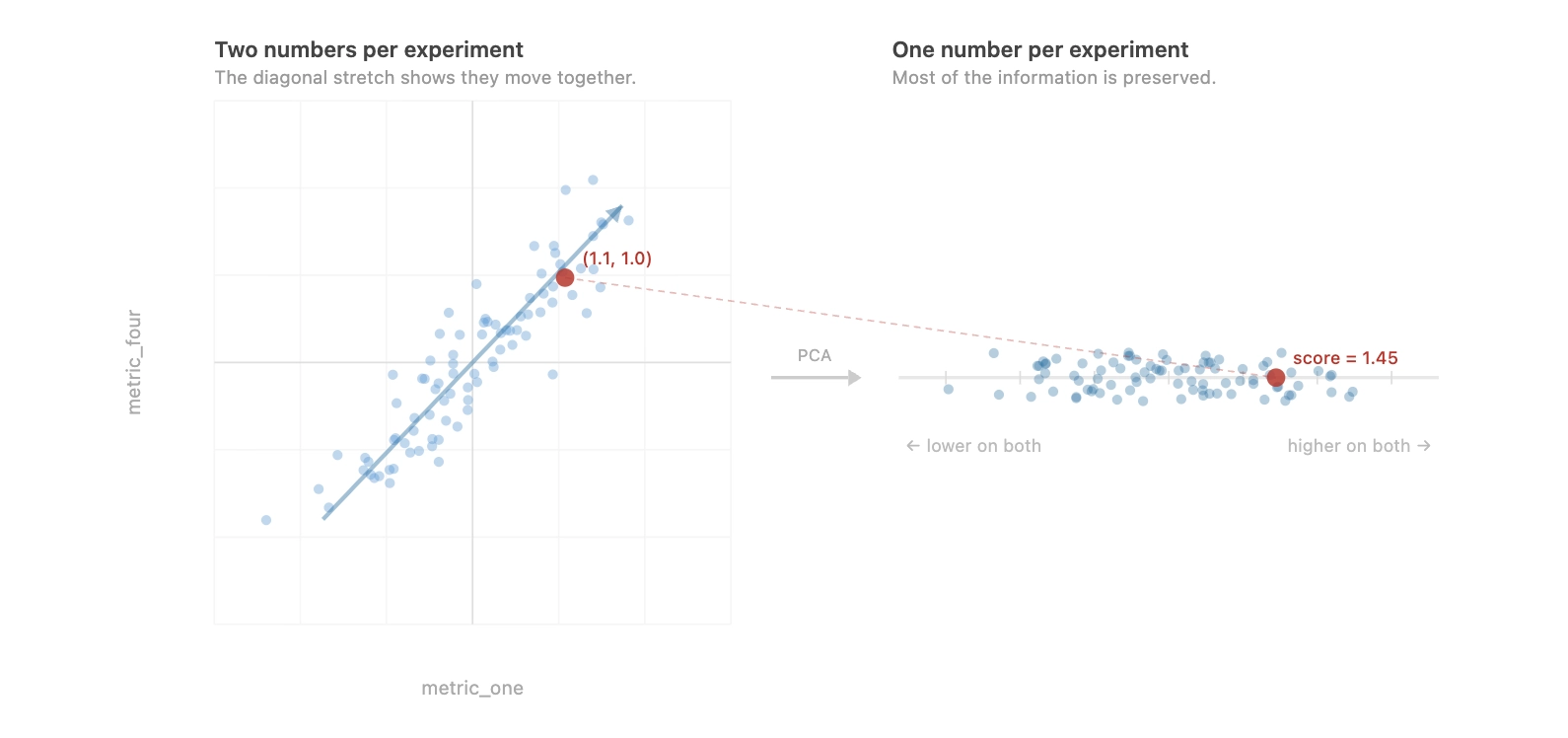
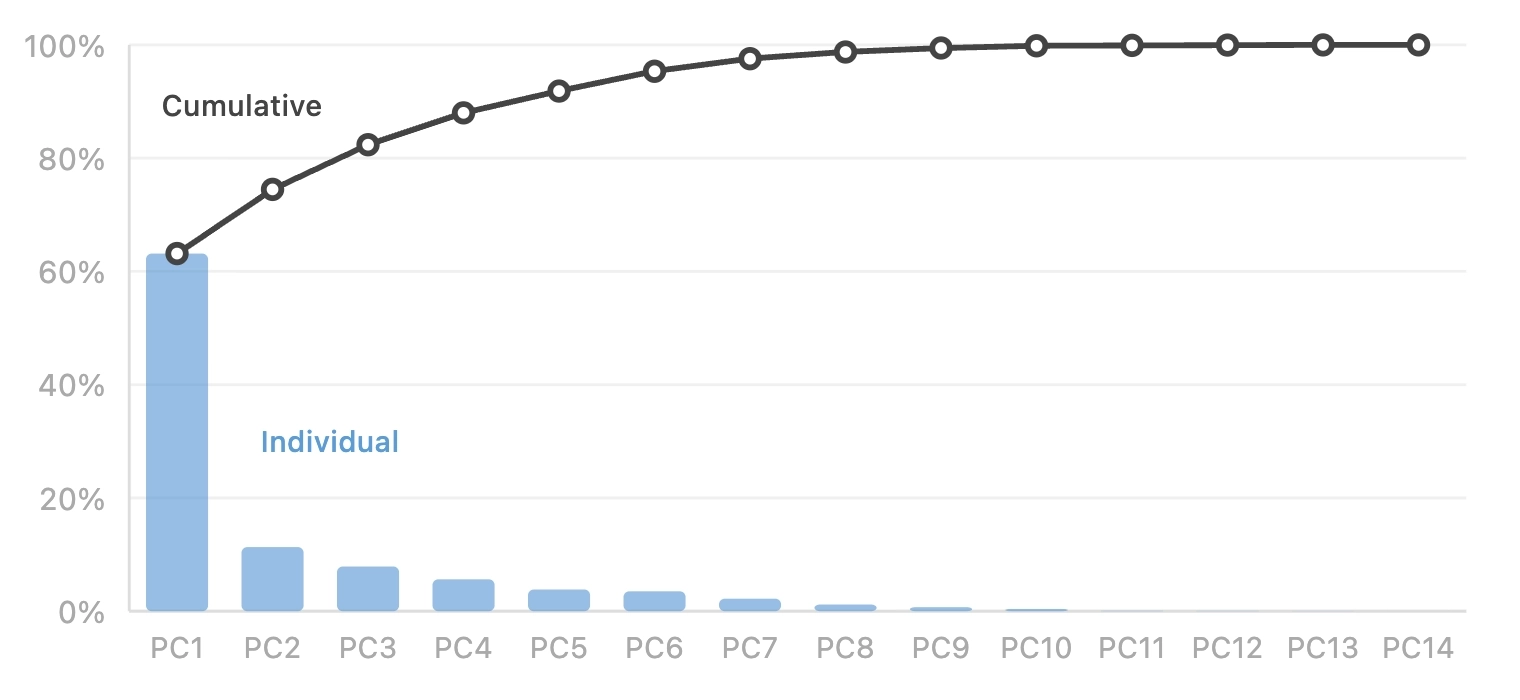
In this article, we explore our journey to address this issue and show that there is no One Fancy Statistical Method™️ to get around this. The best solution is to use fewer, high-quality metrics that capture distinct concepts.









.png)
.png)











Nameplates_BlogBanner_AB_FINAL_V1.png)

_Blog_Banner_Static_Final_1800x720.png)


_MKT_01_Blog%20Banner_Full.jpg)




























.png)















